

L’Olympiade des mathématiques américaines (USAMO) sert de qualification à l’Olympiade internationale en mathématiques et présente une barre beaucoup plus élevée que les tests comme le American Invitational Mathematics Examination (Aime). Bien que les problèmes AIME soient difficiles, ils nécessitent des réponses entières. USAMO exige que les candidats rédigent des preuves mathématiques complètes, notées pour l’exactitude, l’exhaustivité et la clarté sur neuf heures et deux jours.
Les chercheurs ont évalué plusieurs modèles de raisonnement d’IA sur les six problèmes de l’USAMO 2025 peu de temps après leur libération, minimisant toute chance que les problèmes faisaient partie des données de formation des modèles. Ces modèles comprenaient des QWEN QWQ-32B, Deepseek R1Google Gemini 2.0 Flash Thinking (expérimental) et Gemini 2.5 ProOpenai o1-pro et O3-min-de hautAnthropic Claude 3.7 Sonnet avec réflexion étendueet Xai Grok 3.
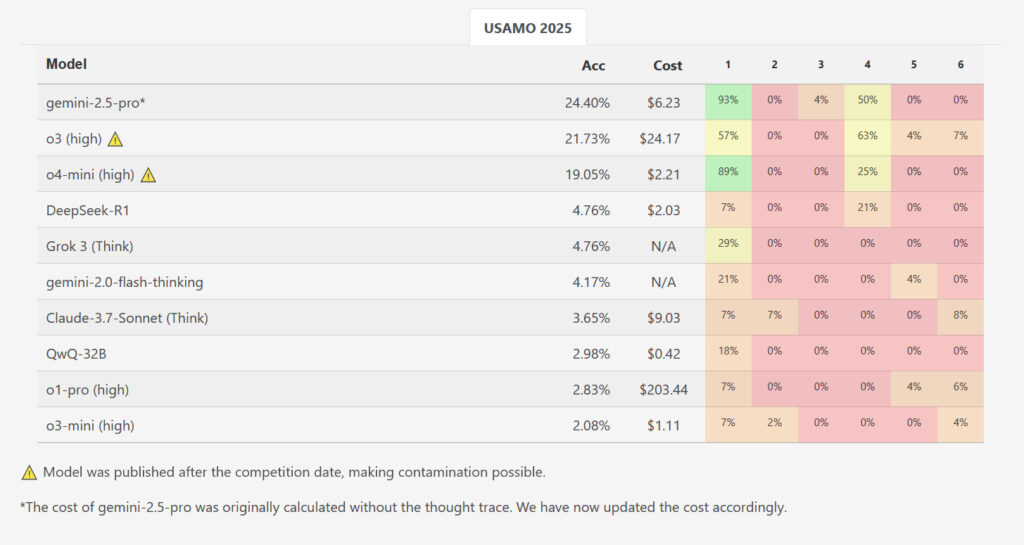
Alors qu’un modèle, Gemini 2.5 Pro de Google, a obtenu un score moyen plus élevé de 10,1 sur 42 points (~ 24%), les résultats ont autrement montré une baisse des performances massive par rapport aux références de niveau AIME. Les autres modèles évalués ont beaucoup retardé en retard: Deepseek R1 et Grok 3 ont en moyenne 2,0 points chacun, le flash-pensant de Google a marqué 1,8, Claude 3.7 d’Anthropic a géré 1,5, tandis que le QWQ de QWEN et O1-PRO d’OpenAI ont en moyenne 1,2 point. O3-Mini d’OpenAI avait le score moyen le plus bas à seulement 0,9 points (~ 2,1%). Sur près de 200 solutions générées sur tous les modèles et courses testés, pas un seul n’a reçu un score parfait pour un problème.
Tandis que Openai est nouvellement sorti 03 et O4-MinI-High n’ont pas été examinés pour cette étude, des références chez les chercheurs ‘ Matharena Le site Web affiche un score O3-High 21,73% dans l’ensemble et un score O4-MinI-haut de 19,05% dans l’ensemble sur USAMO. Cependant, ces résultats sont potentiellement contaminés car ils ont été mesurés après le concours, ce qui signifie que les nouveaux modèles OpenAI auraient pu potentiellement inclure les solutions dans les données de formation.
Comment les modèles ont échoué
Dans l’article, les chercheurs ont identifié plusieurs modèles de défaillance récurrents clés. Les sorties AI contenaient des lacunes logiques dans lesquelles la justification mathématique manquait, comprenait des arguments basés sur des hypothèses non prouvées et a continué à produire des approches incorrectes malgré la génération de résultats contradictoires.
Un exemple spécifique impliqué USAMO 2025 Problème 5. Ce problème a demandé aux modèles de trouver tous les nombres entiers positifs “K”, de sorte qu’un calcul spécifique impliquant des sommes de coefficients binomiaux élevés à la puissance de “K” entraînerait toujours un entier, quel que soit le nombre entier positif “N”. Sur ce problème, le modèle QWQ de QWEN a fait une erreur notable: il a incorrectement exclu les possibilités non entières à un stade où l’énoncé du problème leur a permis. Cette erreur a conduit le modèle à une réponse finale incorrecte malgré avoir correctement identifié les conditions nécessaires plus tôt dans son processus de raisonnement.